

Awal Permulaan
Pada setiap tahap revolusi industri selalu ada teknologi baru yang menggantikan tugas manusia.Salah satu teknologi dalam revolusi industri 4.0 adalah teknologi kecerdasan buatan Kecerdasan buatan dideskripsikan sebagai komputer yang memiliki program yang bisa meniru kemampuan kognitif manusia dalam memecahkan masalah. Selain rule-based, dalam bidang kecerdasan buatan terdapat teknologi machine learning. Machine learning adalah proses pembelajaran melalui suatu algoritme dan model statistik yang digunakan oleh komputer untuk melakukan tugas tertentu tanpa diprogram secara eksplisit. Algoritme machine learning menggunakan sampel data yang sering disebut data training untuk membuat model matematika yang akan digunakan untuk melakukan prediksi dan mengambil keputusan. Pada penelitian ini penulis akan menggunakan kecerdasan buatan dengan metode machine learning untuk memprediksi mood. Mood merupakan perasaan manusia kepada lingkungan sekitar namun tidak spesifik pada satu obyek. Mood berlangsung dalam rentang waktu yang lama namun terbatas, bukan keadaan emosional yang terus melekat pada seseorang. Salah satu metode memprediksi mood adalah menggunakan image recognition pada wajah. Penelitian yang memiliki topik tersebut salah satunya dilakukan oleh Landowska dkk. Landowska dkk memprediksi mood pada peserta e-learning. Kamera diletakkan pada atas dan bawah monitor. Alat pencahayaan diletakkan di belakang monitor. Ternyata memprediksi mood menggunakan image recognition memiliki kekurangan dalam hal kualitas gambar. Posisi wajah, posisi kamera dan pencahayaan sangat berpengaruh terhadap kualitas prediksi.Pada penelitian ini penulis akan melakukan prediksi mood menggunakan lagu yang didengarkan pengguna. Alasan utama lagu layak dipakai untuk memprediksi mood karena menurut paper yang ditulis W. Chijioke mayoritas responden sangat setuju terhadap pernyataan “pendengar memilih lagu berdasarkan mood mereka”
Metode yang Digunakan
Hal pertama yang dilakukan adalah mendapatkan data lagu berbahasa Indonesia. namun tentunya tidak semua lagu berbahasa Indonesaia akan dipakai dalam penelitian ini. Hanya 300 lagu yang paling popular saja yang dipakai. Penulis memakai dataset lebih dari 180 lagu dengan harapan hasilnya diatas 80%. Alasan kenapa dataset tidak memakai lebih dari 300 lagu terpopuler yang dipakai karena semakin tidak popular lagu, maka data lirik lagu nantinya semakin sulit didapatkan. Dengan mempertimbangkan ketersedian layanan penyedia data, maka penulis memutuskan memakai API Spotify karena Spotify menyediakan API untuk melakukan pencarian dan juga menyediakan data popularitas lagu. Pihak Spotify tidak memberitahukan bagaimana data popularitas dihitung. Pada halaman dokumentasinya Spotify hanya memberi informasi bahwa nilai popularitas berkisar dari 0 sampai 100 dan semakin tinggi nilainya maka semakin populer sebuah lagu akhir-akhir ini.
Tahap kedua penulis mengumpulkan data tentang karakteristik audio lagu dalam hal itu penulis menggunakan API spotify. Istilah di dalam API Spotify disebut audio feature. Data- data tersebut sangat mewakili karakteristik sebuah lagu sehingga penulis memutuskan untuk memakai data ini. Data yang disediakan adalah duration, key, mode, time signature, acousticness, danceability,energy, instrumentalness, liveness, loudness, speechiness, tempo dan valence.
Lalu tahap ketiga yang dilakukan adalah mengumpulkan data lirik lagu. Lirik adalah kata-kata yang diungkapkan dalam sebuah lagu. Spotify tidak menyediakan lirik lagu. Oleh karena itu, pada tahap pengumpulan data lirik lagu akan dilakukan proses pengumpulan data dengan API Genius. API Genius hanya menyediakan data URL dari pencarian berdasar judul dan penyanyi. Sehingga setelah URL dari lirik didapat maka tahap selanjutnya menggunakan metode scrapping. Data dari halaman web diunduh dengan format HTML. Lalu dengan pustaka BeautifulSoup akan diambil bagian liriknya saja dan membuang bagian HTML yang tidak penting.
Pada tahap selanjutnya pemberian label mood. Mood yang akan dimasukkan pada dataset seperti yang diperlihatkan pada table dibawah ini :

Lagu akan ditentukan apakah cocok untuk didengarkan saat mood energized-pleasant, calm-pleasant, calm-unpleasant, atau energized-unpleasant. Preprocessing bertujuan membuat data agar siap diolah pada tahap selanjutnya Karena feature ada yang berupa angka dan ada yang berupa teks maka perlu dipisah terlebih dahulu karena akan mengalami proses preprocessing yang berbeda. Feature berupa teks pada penelitian ini adalah lirik lagu. Oleh karena itu lirik lagu akan mengalami text-preprocesssing terlebih dahulu. Text preprocessing ini agar sebuah lirik bisa diekstrak informasi yang ada di dalamnya kemudian direpresentasikan ke dalam angka-angka.
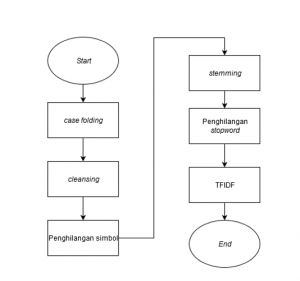
Tahapnya antara lain :
- Case folding
Pada tahap ini semua kata dalam lirik lagu dibuat menjadi huruf kecil. Tujuan utama dari proses ini untuk menunjukkan pada komputer bahwa kata yang yang sama dengan jenis huruf berbeda memiliki makna yang sama, misalkan “Kita” dengan “kita”
- Cleansing
Tahap ini bagian lirik yang tidak penting akan dihilangkan. Pada lirik lagu yang didapat dari Genius.com masih terdapat bagian teks yang kurang penting seperti “[verse]” , “[chorus]” dan sebagainya. Bagian teks ini lebih baik dihilangkan agar model machine learning nantinya fokus pada teks yang penting saja. Penghilangan ini menggunakan metode regex.
- Penghilangan symbol
Tahap ini simbol simbol seperti tanda baca dihilangkan. Tujuannya menyederhanakan teks dengan menghilangkan karakter yang tidak terlalu banyak mengandung informasi.
- Stemming
Tahap ini semua kata dalam lirik lagu dibuat menjadi kata dasar. Tujuannya mengurangi variasi kata agar pada tahap selanjutnya kompleksitasnya bisa dikurangi.
- Penghilangan stopwords
Tahap ini kata yang termasuk kategori stopword dihilangkan karena dianggap tidak memiliki banyak informasi. Stopword biasanya adalah kata sambung yang sangat umum muncul dalam suatu bahasa, dalam kasus ini bahasa yang dimaksud adalah bahasa Indonesia. Tujuannya agar pada tahap selanjutnya hanya kata-kata yang cukup penting saja yang diproses. Daftar stopword yang digunakan mengikuti pustaka Sastrawi.
- TF IDF
tahap ini informasi dari lirik lagu yang telah melalui berbagai proses sebelumnya akan diekstrak. Hasil TFIDF menghasilkan angka-angka yang merupakan representasi dari lirik lagu dan tetap berusaha meminimalkan hilangnya informasi. Proses ini dilakukan dengan menghitung Term Frequency lalu dikalikan dengan nilai Inverse Document Frequency.
Setelah feature teks diubah menjadi angka maka akan digabungkan dengan feature yang sudah berupa angka sejak awal. Setelah itu gabungan feature tadi akan mengalami proses preprocessing lainnya. Proses preprocessing yang dimaksud antara lain :
- Imputation
Tahap ini nilai yang kosong dalam data diganti menjadi median dari kolom asal data yang kosong tersebut. Tahapan ini harus dilakukan karena jika tanpa disadari ada data yang kosong maka tahap selanjutnya tidak dapat dilakukan.
- Standardization
Tahap ini data angka akan diubah atau ditransformasi. Tujuannya untuk mengubah data agar tiap feature memiliki mean mendekati nol dan standar deviasi mendekati satu.
- Feature selection
tahap feature-feature yang dianggap terbaik akan dipilih. Feature-feature yang terpilih adalah feature-feature yang akan diproses oleh algoritme machine learning. Untuk menilai mana feature – feature terbaik ada banyak cara . Pada ini nilai ANOVA-lah digunakan untuk memilih feature yang dianggap terbaik. Data yang sudah mengalami semua tahap preprocessing berarti siap untuk memasuki tahap pelatihan dan pengujian model. Data kemudian dipecah menjadi data training dan data test dengan metode 10 fold cross validation. Pada penelitian ini jenis proses yang akan dilakukan adalah multiclass classification. Algoritme machine learning yang telah ditentukan akan melakukan proses training secara bergantian. Pada setiap algoritme machine learning juga diterapkan nilai regularization yang berbeda.
Pada tahap implementasi machine learning pada aplikasi. model dengan accuracy terbaik akan diimplementasikan pada aplikasi berbasis web. Selain itu akan dibuat user interface sederhana untuk petunjuk proses dan menampilkan hasil. Pada tahap validasi akan dilakukan survei pada responden untuk mengetahui apakah aplikasi bisa memprediksi mood dengan benar menurut pendapat responden. Jumlah responden sekitar 30 orang. Responden akan ditanyai apakah hasil prediksi mood sudah akurat atau tidak menurut mereka.
Pengujian Design
Responden akan dipakai untuk proses penilai tentang keakurata prediksi mood. Responden yang dipakai adalah pengguna Spotify, berumur 15 sampai 35 tahun. berprofesi sebagai mahasiswa dan berdomisili di Yogyakarta Alasan responden yang dipilih harus pengguna Spotify karena salah satu proses pada penelitian ini adalah pengambilan data dari akun Spotify. Alasan responden yang dipilih berada di rentang umur 15 sampai 35 tahun karena pengguna Spotify 84% berada pada rentang umur ini. Alasan responden yang dipilih berprofesi mahasiswa dan berdomisili di Yogyakarta karena mudah dijangkau oleh penulis. Aplikasi web akan ditunjukkan ke responden menggunakan laptop penulis. Responden akan diminta untuk masuk ke akun Spotify-nya dan memberikan izin aplikasi web ini untuk mengakses data. Aplikasi web akan mengambil data 20 lagu terakhir yang didengarkan responden. Alasan 20 lagu terakhir yang dipakai karena API Spotify secara default memberikan data 20 lagu terakhir. Untuk mengurangi parameter penelitian penulis tidak memakai variasi lain dalam hal jumlah lagu terakhir yang dibaca oleh aplikasi web. Pada tahap terakhir, responden diminta untuk memberikan penilaian. Pemberian penilaian menggunakan lima pilihan yaitu sangat tidak akurat, tidak akurat, cukup akurat, akurat dan sangat akurat. Penentuan jumlah pilihan yang disediakan, yaitu lima, mengikuti paper W. Chijioke.
Hasil Sistem
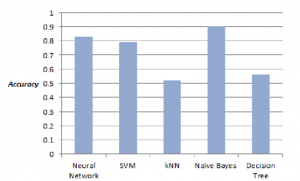
Terdapat dua jenis model yang akan dibuat. Model yang melibatkan lirik dan model tanpa melibatkan lirik. Yang pertama dibahas adalah model yang melibatkan lirik. Grafik dibawah ini merupakan perbandingan accuracy terbaik yang didapatkan tiap algoritme :
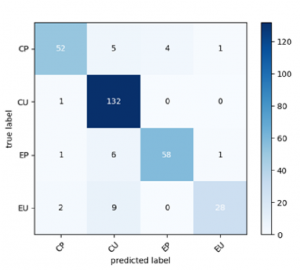
Selanjutnya terdapat confusion matrik dari model dengan lirik sebagai salah satu fitur yang didapatkan :
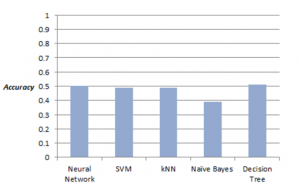
Model yang kedua yang akan dibahas adalah model yang hanya menggunakan audio feature . Pada grafik dibawah merupakan accuracy terbaik yang didapatkan tiap algoritma
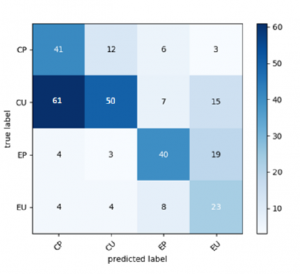
Lalu terdapat Confusion matrik dari model yang hanya melibatkan audio feature terlihat pada gambar dibawah ini
Terdapat grafik penilaian dari pengguna yang menilai keakuratan prediksi mood pengguna yang terlihat pada gambar dibawah ini
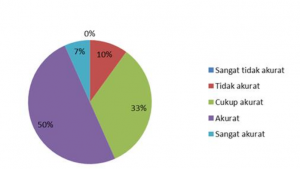
- 7% responden menilai bahwa aplikasi sangat akurat dalam memprediski mood mereka
- 50% responden menilai bahwa aplikasi akurat dalam memprediksi mood mereka
- 33 % responden menilai bahwa aplikasi cukup akurat dalam memprediksi mood mereka
- 10% responden menilai bahwa aplikasi tidak akurat dalam memprediksi mood mereka
- 0% responden menilai bahwa aplikasi sangat tidak akurat dalam memprediksi mood mereka
Saran Pengembangan Sistem
Dalam pengembangan sistem dasbor ini masih memiliki beberapa kekurangan yang bisa dikembangkan pada penelitian selanjutnya. Berikut adalah beberapa saran dan solusi yang bisa dilanjutkan dari penelitian ini.
- Dataset yang digunakan seharusnya lagu populer dari berbagai macam bahasa. Hal tesebut dikarenakan saat melakukan survei banyak responden yang mendengarkan lagu berbahasa asing seperti lagu berbahasa Inggris, Korea dan Jepang. Jika memakai lagu berbahasa asing, tentunya sampel data lagu yang dibutuhkan menjadi jauh lebih banyak. Dengan sampel data lagu yang jauh lebh banyak dan bahasa yang bervariasi, membutuhkan preprocessing yang lebih beragam.
- Untuk penelitian yang berkaitan dengan psikologi lebih baik melibatkan pihak yang mengerti tentang psikologi manusia agar hasilnya lebih akurat,valid dan kredibel.




{kind=link}
{kind=link}
One thought on “IMPLEMENTASI MACHINE LEARNING UNTUK MEMPREDIKSI MOOD PADA LAGU”
Saya Tertarik Untuk Melakukan Pengembangan Terhadap Topik Ini, Apakah Saya Dapat Menghungi Penulis Yang Bersangkutan