

Seiring dengan meningkatnya kemudahan akses internet, informasi berkembang dan menyebar dengan sangat cepat. Kemajuan di bidang teknologi informasi dan telekomunikasi berdampak pada munculnya berbagai portal berita online. Arus informasi tidak lagi dikuasai oleh televisi, radio, koran, dan majalah. Masyarakat Indonesia kini mulai beralih dari konsumsi berita dalam bentuk surat kabar ke koran digital atau situs berita online. Jumlah berita yang tersimpan dalam format elektronik terus meningkat. Berita dapat diolah dan digunakan perusahaan untuk mendapatkan informasi tentang sentimen opini publik terhadap perusahaan. Membaca satu per satu berita yang ada di portal berita membutuhkan waktu yang lama. Oleh karena itu diperlukan suatu teknik yang mampu mengklasifikasikan berita tersebut ke dalam positif, netral, dan negatif secara otomatis untuk menganalisis data yang dapat berguna dalam proses pengambilan keputusan. Pada penelitian ini akan dilakukan pengembangan aplikasi web untuk mengukur analisis sentimen pada berita e-commerce berbahasa Indonesia dengan menerapkan metode pembobotan TF-IDF dan metode machine learning yaitu Support Vector Machine. Data yang digunakan merupakan data berita berbahasa Indonesia tentang e-commerce di Indonesia yang berasal dari Bing News. Evaluasi model dilakukan dengan metode 5-fold cross validation.
Awal Permasalahan
Berita mengenai e-commerce banyak dibahas di Bing News. Terlebih Indonesia merupakan pasar terbesar e-commerce di Asia Tenggara. Berbagai macam berita di situs Bing News tentu saja akan mempengaruhi citra dari perusahaan e-commerce. Berita yang baik akan membentuk opini yang baik pula dari konsumen tentang produk/jasa. Pada bisnis e-commerce, mengukur kepuasan pelanggan menjadi hal yang penting, yaitu untuk mengetahui apakah sistem pada e-commerce tersebut sudah sesuai dengan harapan dari pelanggan. Oleh sebab itulah, pada penelitian ini topik berita yang dipilih adalah e-commerce. Jumlah berita yang tersimpan dalam format elektronik terus meningkat, sehingga pihak perusahaan sulit memperoleh informasi secara keseluruhan dari semua berita, karena akan membutuhkan waktu yang lama untuk membaca satu per satu berita yang ada di portal berita. Oleh karena itu diperlukan suatu teknik analisis sentimen yang mampu mengklasifikasikan berita tersebut ke dalam positif, netral, dan negatif secara otomatis untuk menganalisis data yang dapat berguna dalam proses pengambilan keputusan.
Pengembangan Aplikasi
Tahapan kerja dari penelitian yang dirancang ditunjukan dengan diagram alir pada Gambar dibawah ini :
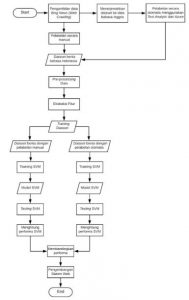
Dataset yang akan digunakan adalah berita dari Bing News. Berita dari Bing News dipilih karena telah terverifikasi. Dataset tersebut terdiri dari berita berbahasa Indonesia yang mengandung sentimen kata kunci e-commerce di Indonesia yang diambil selama batasan waktu yang telah ditentukan. Data diperoleh melalui cara web crawling dan dilakukan menggunakan Bing News API dari Microsoft Azure. Pengambilan data dilakukan selama kurang lebih dua bulan mulai tanggal 16 April hingga 14 Juni. Keluaran yang dihasilkan dari web crawling ini adalah sekumpulan berita yang disimpan dalam file dengan format Comma Separated Value (CSV). Total jumlah data yang digunakan dalam penelitian ini sebanyak 334 berita. Sebelum dapat melakukan crawling, sistem ini akan melakukan pengecekan subscription key apakah sudah terdaftar pada Microsoft Azure. Berita dari Bing News yang telah dicrawling akan diklasifikasikan menjadi 3 jenis sentimen yaitu positif, negatif, dan netral.

Pada tabel I terdapat kolom berita dan sentimen. Kolom berita berisi data judul dan data deskripi dari hasil crawling. Pada kolom sentimen, nilai 1 menunjukkan sentimen positif, nilai 0 menunjukkan sentimen netral, dan nilai -1 menunjukkan sentimen negatif. Nilai ini akan digunakan sebagai tolak ukur berita dikatakan positif, negatif, atau netral pada saat pelatihan data. Tahap selanjutnya adalah melakukan preprocessing untuk menghilangkan bagian yang tidak diperlukan dalam analisis sentimen sehingga data akan lebih terstruktur. Dalam preprocessing terdapat beberapa tahap, secara berurutan adalah case folding, cleansing, stemming, penghapusan stopword, dan tokenisasi. Pada penelitian kali ini metode pembobotan kata yang digunakan adalah TF-IDF atau Term Frequency – Inverse Document Frequency. Tujuan dari pembobotan kata adalah agar data dapat diubah ke dalam bentuk vektor sehingga data dapat melalui proses klasifikasi. Proses klasifikasi dan prediksi dilakukan dengan algoritma Support Vector Machine. Selanjutnya adalah tahap evaluasi bertujuan untuk mengukur keakuratan hasil klasifikasi. Semakin besar hasil akurasi, maka kinerja model klasifikasi semakin bagus. Tahap terakhir adalah pengembangan sistem web Sistem web terkoneksi dengan News API untuk mengambil berita yang akan diuji.
Hasil Pengembangan Sistem
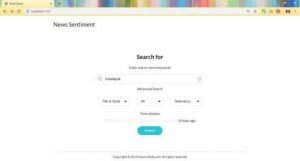
Halaman fungsional yang terdapat pada sistem web ini antara lain adalah halaman build query, halaman result, dan halaman insight. Pada halaman build query, pengguna dapat mengatur pencarian berita berdasarkan fitur-fitur di dalam halaman tersebut. Pada halaman ini disajikan form input pencarian yang digunakan untuk proses crawling suatu kata kunci. Data yang akan ditampilkan pada halaman result dan insight adalah berdasarkan time window yang telah diatur oleh user. Rentang waktunya adalah mulai dari berita satu hari yang lalu hingga tiga puluh satu hari yang lalu. Terdapat batasan dalam rentang waktu karena API yang digunakan bersifat gratis. Terdapat dua opsi pencarian, yaitu title and body yaitu kata kunci atau frasa yang harus dicari dalam judul dan isi artikel dan title only yaitu kata kunci atau frasa yang harus dicari dalam judul artikel saja. Pengguna juga dapat mengatur berita yang ditampilkan berdasarkan pilihan sentimen yaitu positif, negatif, netral, dan all (pengguna dapat melihat semua sentimen). Pengguna juga dapat mengurutkan berita yang dicari berdasarkan karakteristik berita seperti relevancy yaitu mengurutkan dari artikel yang lebih dekat hubungannya dengan keyword, popularity yaitu mengurutkan dari artikel yang sumber dan penerbitnya paling popular, publishedAt yaitu mengurutkan dari artikel terbaru. Ketika user menekan tombol search, sistem akan mengolah data hasil crawling sehingga dapat menampilkan hasil sentimennya pada halaman result.
Dibawah ini merupakan Gambar Built Query :
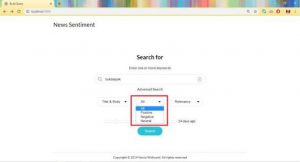
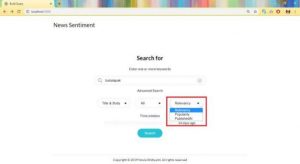
Dan ini pada hasil penelitian ini terdapat Gambar Opsi pencarian, Opsi sentimen dan Sort by
Halaman result menampilkan hasil pencarian berita dari berbagai sumber kepada pengguna sesuai dengan pengaturan pada halaman build query. Komponen yang ditampilkan pada halaman ini adalah gambar berita, judul berita, tanggal diterbitkan, deskripsi berita, dan hasil sentimen. Gambar dibawah ini menunjukkan jumlah masing-masing sentimen yaitu positif, negatif, dan netral di setiap tanggal yang telah ditentukan
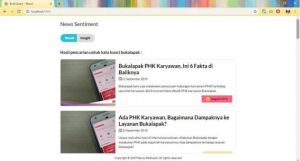
Halaman insight disediakan untuk memahami lebih mendalam mengenai karakteristik berita yang dicari. Pengguna dapat memanfaatkan wawasan yang diperoleh pada halaman ini untuk proses evaluasi sesuai dengan kepentingan pengguna. Pada halaman insight, penulis membuat 3 fitur, yaitu stories over time direpresentasikan dengan line chart, overall sentiment direpresentasikan dengan pie chart, dan wordcloud.
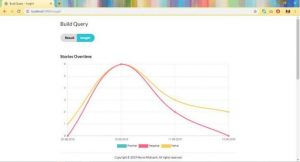
Gambar diatas fitur line chart yang menunjukan total masing masing sentimen dari semua tanggal yang dipilih.
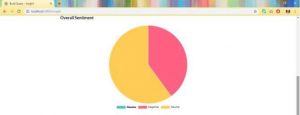
Gambar diatas merupakan fitur dari Pie Chart yang menunjukkan kata-kata yang sering muncul pada keseluruhan berita. Halaman insight disediakan untuk memahami lebih mendalam mengenai karakteristik sentimen berita yang didapatkan.




{kind=link}
{kind=link}
{kind=link}
{kind=link}