
Menambahkan kecerdasan buatan saat ini sudah tidak sesulit sebelumnya. Banyak platform layanan kognitif yang tersedia untuk digunakan. Sebut saja Azure Cognitive Service, Amazon Lex, sampai Google Dialog Flow.
Salah satu implementasi dari kecerdasan buatan ini adalah pada chatbot. Hanya saja, saat ini kecerdasan buatan masih berfokus pada yang berbahasa Inggirs. Sehingga, muncul pertanyaan sabagai berikut:
- Bisakah menambahkan kemampuan pada chatbot non-berbahasa inggirs?
- Bagaimana agar cognitive service dapat meningkatkan performa sentimen analisis pada chatbot?
Untuk menjawab pertanyaan di atas, kami melakukan riset dengan batasan sebagai berikut:
- Riset ini menggunakan aplikasi web sebagai pengembangannya. Hal ini didasari bahwa populasi aplikasi website masih paling tinggi dibandingkan dengan aplikasi mobile atau desktop.
- Riset ini akan menggunakan metode Scrum pada pengembangannya. Scrum dipilih karena metode ini paling umum digunakan dalam lingkungan pengembangan modern.
- Riset ini menggunakan layanan kognitif berbasis Azure. Hal ini dipilih karena pada saat riset ini dilaksanakan, Azure mempunyai layanan kognitif yang paling beragam di antara yang lain.
Sedangkan alat yang digunakan pada riset ini adalah sebagai berikut:
- Microsoft Visual Studio 2017 sebagai aplikasi untuk pengebangan web.
- Azure DevOps digunakan sebagai asisten pengelolaan metode Scrum.
- Azure Cognitive Services. Layanan ini menyediakan analisis sentimen yang digunakan oleh aplikasi
- Azure Machine Learning Studio. Alat ini menyediakan kemampuan untuk memodifikasi layanan kognitif azure yang ada.
Artikel ini menggunakan Scrum untuk memfasilitasi metode rekayasa perangkat lunak. Perangkat lunaknya nanti akan mempunyai fitur sebagai berikut:
- Menyediakan analisis sentimen dari produk berdasarkan Twitter dan News
- Membandingkan analisis sentimen dari dua produk berdasarkan Twitter dan News
- Menyediakan percakapan pesan instan untuk pengguna
Pada Scrum, fitur tersebut dibagi menjadi backlog sebagai berikut:
- Sebagai visitor, saya dapat menanyakan sentimen produk sehingga saya mendapatkan informasi mengenai produk.
- Sebagai visitor, saya dapat membandingkan sentimen produk sehingga saya mendapatkan rekomendasi antara dua produk
- Sebagai visitor, saya dapat meminta chatbot dengan bahasa percakapan sehingga dapet menyediakan informasi melalui jendela pesan instan.
Backlog di atas dikerjakan dalam tiga iterasi. Iterasi pertama, fokus pada interaksi chatbot dan menggabungkan layanan kognitif. Sedangkan iterasi kedua, lebih fokus pada analisis produk. Dua iterasi ini dikerjakan dalam waktu dua bulan.
Desain eksperimen yang ditawarkan adalah sebagai berikut:
- Dataset. Dataset dikumpulkan dari dua sumber yaitu berita dari Bing dan Twitter. Dataset terdiri dari 2000 item untuk tiap Twitter dan Bing News pada 45 produk. Sehingga total dataset adalah 90.000 item untuk tiap Twitter dan Bing News.
- Rancangan Percobaan. Ada dua rancangan percobaan. Pertama, menggunakan pre-processing dan yang kedua tanpa pre-processing. Pre-processing yang digunakan adalah Latent Semantic Analysis (LSA) dan Latent Dirichlet Allocation (LDA).
- Evaluasi Hasil. Hasilnya akan dievaluasi menggunakan MAE (Mean Absolute Error) dan pendekatan waktu eksekusi.
Latent Semantic Analysis
Latent Semantic Analysis (LSA) merupakan metode topic modelling paling dasar. LSA menganalisa hubungan antara sekumpulan dokumen dan istilah yang terkandung. LSA menggunakan document-term-matrix yang berisi bobot term pada beberapa dokumen. Bobot tersebut merupakan hasil perhitungan TF-IDF (Term Frequency – Inverse Document Frequency). Document-term-matrix kemudian diproses menggunakan Singular Value Decomposition menghasilkan term-topic matrix. Term-topic matrix dapat digunakan untuk mencari terms yang mirip menggunakan metode cosine similarity.
Latent Dirichlet Allocation
Latent Dirichlet Allocation (LDA) merupakan teknik pembelajaran mesin tak terbimbing yang digunakan untuk mengklasifikasi text pada sebuah dokumen ke dalam beberapa topik. Dalam hal ini LDA tidak memerlukan kelas berlabel kemudian menyimpulkan data ke dalam kelas tersebut, melainkan LDA akan membuat model probabilistik yang digunakan untuk mengelompokkan topik. Secara singkat algoritme LDA adalah sebagai berikut.
- Proses setiap dokumen dan masukkan tiap kata pada dokumen pada salah satu topik K
- Proses tersebut memberikan representasi topik pada semua dokumen dan distribusi kata pada semua topik
- Setiap dokumen d, hitung setiap kata w dalam dokumen d
- proporsi dokumen yang termasuk dalam suatu topik t ; p(topik t | dokumen d).
- proporsi penempatan topik t pada semua dokumen d yang berasal dari kata w; p(kata w| dokumen d).
- Tentukan kata w pada topik baru t’ dimana pilih topik t’ dengan probabilitas p(topik | dokumen d) * p(kata w| dokumen d).
Dari proses di atas, didapatkan n topik yang terdiri atas kumpulan kata. Kumpulan kata pada topik tersebut dapat kita batasi jumlahnya dengan mengurutkan kata dari probabilitas kata pada suatu topik tertinggi.
Proses percobaannya sebagai berikut:
- Dataset dikumpulkan dengan bantuan API Twitter dan Bing News. Dikumpulkan sekitar 2000 data berita dan twit.
- Aplikasi dikembangkan menggunakan layanan kognitif. Twit dari Bahasa Indonesia diterjemahkan ke Bahasa Inggris. Hasil keluran dari proses layanan kognitif dilabeli dengan nama “CS Result”.
- Dataset juga akan dilakukan pre-processing sebelum masuk pada layanan kognitif.
- Proses pre-processing seperti disebutkan di atas adalah LSA dan LDA. Hasil proses dengan LSA akan dilabeli dengan “LSA+CS”. Sedangkan hasil dari LDA dilabeli dengan “LDA+CS”.
- Hasil dari analisis sentimen “CS Result” dibandingkan dengan “LSA + CS” dan “LDA + CS”. Bagian yang dibandingkan adalah kecepatan proses dan kesamaan hasil dari keduanya.
- Hasil terbaik akan dipasangkan ke aplikasi chatbot untuk pengujian.
Kami melakukan dua jenis evaluasi. Pertama, Mengukur Mean Absolute Error (MAE) antara “CS Result” dengan “LSA+CS” dan “CS Result” dengan “LDA+CS”.
Hasil MAE dari LSA+CS mendapatkan hasil dari Twitter dan News adalah 0.1278 dan 0.1043, sedangkan LDA+CS adalah 0.1258 dan 0.0813 untuk hal yang sama.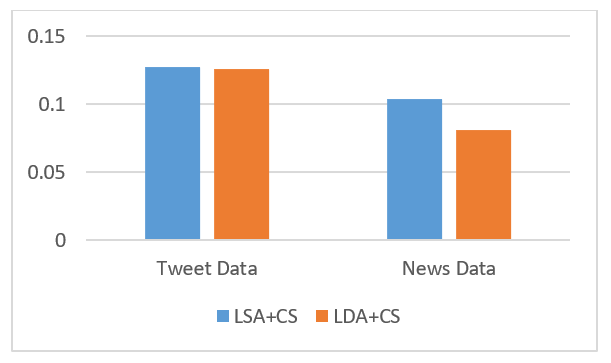
Kedua, mengukur waktu eksekusi dari dataset yang diambil dari sumber (Twitter dan News) dibandingkan antara yang diproses dengan LDA dan LSA dengan tanpa pemrosesan terlebih dahulu sebelum dimasukkan ke dalam layanan kognitif.
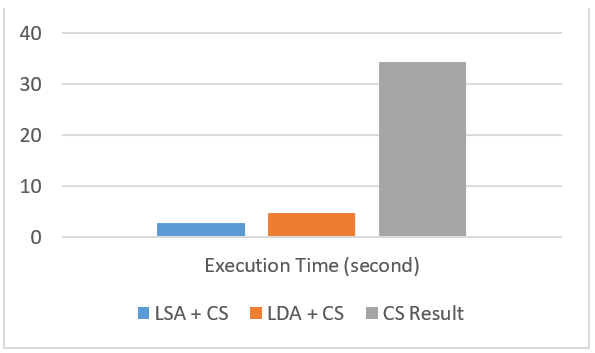
Hasilnya, waktu eksekusi yang dihasilkan dari “LSA+CS”, “LDA+CS”, dan “CS Result” secara berurutan adalah 2.7527 detik, 4.6944 detik, dan 34.3521 detik.
Berdasarkan implementasi dan percobaan di atas, kami dapat menjawab pertanyaan di awal sebagai berikut:
- Layanan kognitif dapat digunakan untuk memberikan fasilitas pengukuran analisis sentimen untuk non-bahasa Inggris. Hal ini dapat dilakukan dengan menerjemahkan dari bahasa Indonesia ke English terlebih dahulu kemudian mengukur analisis sentimennya. Proses dengan LDA+CS menunjukkan nilai MAE terendah dengan hasil 0.1258
- Pre-prosesing menambahkan aktivitas pengukuran analisis sentimen. Namun kehadirannya justru mempercepat perhitungan analisis sentimen. LSA+CS menunjukkan hasil eksekusi paling cepat dengan 2.75 detik dibandingkan tanpa pre-processing yaitu 34.35 detik.


