
Data is Everything and Everything is Data
Pada zaman digital sekarang data menjadi salah satu hal terpenting yang mendorong perkembangan teknologi, terlebih lagi teknologi kecerdasan buatan. Dalam pembangunan sebuah sistem kecerdasan buatan (terutama machine learning), data dalam jumlah besar (dataset) dibutuhkan untuk digunakan pada proses pelatihan sistem tersebut. Sebenarnya sudah banyak dataset yang tersedia dari luar negeri untuk digunakan dalam pelatihan model kecerdasan buatan, namun hal ini sedikit bermasalah pada sistem kecerdasan buatan yang membutuhkan data teks. Pada sistem ini, data teks yang digunakan harus sesuai dengan bahasa sistemnya, contohnya dalam pembuatan sistem kecerdasan buatan berbahasa Indonesia, dibutuhkan pula data teks yang berbahasa Indonesia.
Memperkenalkan Dataset bahasa Indonesia
Pada kesempatan ini, kami menyajikan sebuah dataset teks berbahasa Indonesia yang disesuaikan untuk pembangunan sistem analisis sentimen. Dataset ini dikumpulkan melalui media sosial twitter dan mengandung 10.806 baris data berupa tweet bahasa Indonesia yang dikategorikan kedalam tiga polaritas yaitu positif, negatif, dan netral.
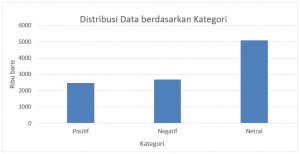
Pengujian Data
Untuk Memastikan bahwa data yang disediakan benar-benar sesuai untuk digunakan dalam proses pelatihan analisis sentimen. Data kami (data primer) akan dibandingkan dengan dataset SemEval-2018 (data sekunder) yang merupakan dataset dari konferensi Semantic Evaluation dari segi akurasi setelah digunakan untuk pelatihan model.

Berdasarkan pengujian yang dilakukan, terlihat bahwa dataset bahasa Indonesia yang disediakan memiliki nilai akurasi yang hampir sama dengan data pembanding dan dengan demikian, disimpulkan bahwa dataset ini sesuai untuk digunakan dalam proses pelatihan analisis sentimen berbahasa Indonesia.
Masa Depan Dataset
Kedepanya, penulis berharap untuk dapat tetap memperbaharui dataset bahasa Indonesia ini antara lain dengan :
- Meningkatkan jumlah data pada dataset dengan menambahkan tweet-tweet baru kedalam dataset.
- Meningkatkan kualitas data pada dataset dengan cara melakukan penyaringan yang lebih intensif dari tweet–tweet yang diambil.
- Menambahkan kategori emosi yang lebih spesifik pada dataset, misalnya senang, sedih, marah, dan lain-lain.



