

Pahami bahasa Kucing ciptakan ikatan emosi
Kucing adalah salah satu hewan yang difavoritkan untuk menjadi peliharaan. Tak jarang, pecinta kucing dibuat gemas dengan tingkah laku dari hewan berbulu ini.Namun, siapa sangka suara meong yang dihasilkan kucing setiap kali menyampaikan keinginannya kini dapat diterjemahkan ke dalam bahasa manusia beserta emosinya. Seorang peneliti telah menciptakan aplikasi unik yang dapat menerjemahkan ‘bahasa kucing’ ke dalam bahasa yang dimengerti oleh manusia. Nama aplikasinya adalah Catsign mungkin ada kiranya saat anda ingin membantu dipengembangan ini bisa mendownload aplikasinya dengan mencari “CATSIGN” menggunakan tanda petik dan huruf capital dan didownload gratis .
Sementara itu pengembangan catsign, peneliti menerapkan jaringan saraf konvolusional untuk melakukan klasifikasi suara dari berbagai suara yang dibuat oleh kucing. Data terdiri dari suara kucing yang dilabeli sebagai emosi. Model kemudian akan digunakan untuk mengklasifikasikan emosi ini berdasarkan suara kucing. Untuk melakukan itu, peneliti melakukan ekstraksi fitur dengan koefisien mel-frequency cepstral coefficients (MFC) yang merupakan koefisien kolektif cepstrum frekuensi mel. Peneliti akan membahas arsitektur CNN dengan fitur yang dihasilkan oleh MFCcs dengan kinerja scorenya
Rahasia dapur sang pengembang
Penggunaan jaringan saraf konvosional
Convolutional Neural Network adalah kelas dari deep neural network yang dibangun berdasarkan model multilayer perceptron. lapisan konvolusional ini masing-masing terdiri dari beberapa neuron atau node yang saling terhubung ke lapisan berikutnya dan ditumpuk bersama-sama untuk membangun arsitektur yang dalam. CNN dibangun di atas Setiap titik data dan kemudian akan dipasang ke lapisan ini sehingga model peneliti dapat mempelajari fitur hierarki tingkat tinggi dari data yang sudah ada.
MEL-FREKUENSI CEPSTRUM
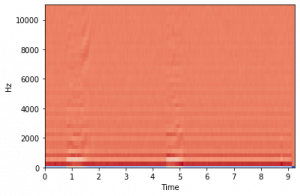
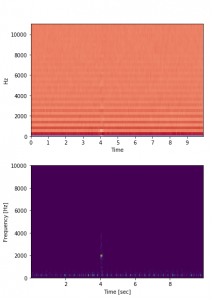
Mel-frequency cepstrum adalah representasi visual suara sebagai spektrum, seperti spectrogram. Koefisien cepstral frekuensi mel adalah koefisien yang membentuk MFC. Dalam MFCC, setiap bin frekuensi berjarak secara kuasi-logaritma kira-kira menyerupai resolusi sistem pendengaran manusia dibandingkan dengan ogramr spect standar yang memiliki jumlah hertz yang sama untuk setiap ruang bin frekuensi. Ini membuat MFC memiliki fitur yang lebih terinspirasi biologis dan berkinerja lebih baik dalam pengenalan ucapan dan pemisahan serta dalam klasifikasi suara hewan . Contoh lain dari representasi frekuensi waktu yang dapat digunakan untuk klasifikasi suara hewan adalah spectogram berbasis komponen harmonik dan spectogram berbasis komponen perkusif .
Angka ini kemudian dapat diukur berdasarkan jumlah koefisien yang ditentukan dan laju sampel audio. Hasil visualisasi MFCCs dapat dilihat di Gbr. 2
Set Data
Peneliti akan mengumpulkan data dari ontologi audio berlabel manusia yang disebut audioset. Setiap entri audioset adalah klip suara berjarak 10 detik yang diambil dari video YouTube. Dari ontologi ini, peneliti akan mengambil data suara yang dikategorikan sebagai data suara kucing. Kategorisasi data ini terdiri dari mendengkur yang merupakan suara yang dibuat oleh kucing untuk menunjukkan kesenangan santai, mengeong yang merupakan komunikasi nada klasik yang dibuat oleh kucing, mendesis yang merupakan suara ketika kucing memberikan peringatan atau menunjukkan ketidaksetujuan, caterwaul, yang merupakan suara yowling yang dibuat oleh kucing dalam panas, dan menggeram yang merupakan tanda agresi atau ekspresi kemarahan dari kucing.
Hasil Eksperimen yang diharapkan
Mengumpulkan Data
Sebelum menuju hasil, peneliti mengumpulkan data untuk memilih data berdasarkan label tertentu pada audioset. Label yang kita pilih lebih murni, mengeong, menggeram, mendesis, dan caterwaul. Masing-masing suara ini akan digunakan untuk menginterprasi suara kucing tertentu. Mendengkur dikategorikan bahagia atau santai, mengeong dikategorikan netral, menggeram dikategorikan sebagai kemarahan atau agresi, mendesis dikategorikan berhati-hati atau tegang, dan katering dikategorikan kesepian.
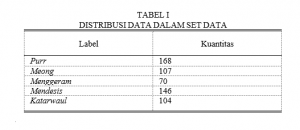
Audioset pada suara kucing terdiri dari 3.964 data. Tetapi, karena sifat ontologi itu sendiri, data pada audioset dapat terdiri dari beberapa label, peneliti memilih untuk mengumpulkan data yang hanya memiliki label yang ditentukan(purr, meow, menggeram, mendesis, dan katerwaul) dan tidak ada yang lain. Beberapa data dari audioset juga tidak tersedia karena video di youtube dihapus atau tidak tersedia di negara kita. Pada akhirnya peneliti berhasil mengumpulkan 595 data yang dibagi menjadi 5 labels yang dapat dilihat pada Tabel1
Terbatasnya jumlah data tidak diragukan lagi akan mempengaruhi kinerja model peneliti. Bahkan lebih, jumlah data yang tidak seimbang pada setiap label juga akan mempengaruhi kinerja dengan cara negatif. Di masa depan peneliti berharap untuk melakukan eksperimen ini dengan jumlah tambahan dan data yang lebih seimbang.
Setiap data dalam audioset ditautkan ke video youtube tertentu yang berisi suara dan cap waktu dalam durasi 10 detik. Untuk proses pengunduhannya sendiri, peneliti akan menggunakan perangkat lunak sumber terbuka yang disebut FFmpeg dan skrip python. peneliti akan mengunduh bagian audio video youtube pada stempel waktu yang ditentukan dengan laju sampel 44100, 2 saluran, kedalaman 16 bit, dan format .flac.
Transformasi Data
Sebelum peneliti dapat menggunakan data audio untuk melakukan pelatihan model, pertama, peneliti melakukan proses transformasi pada data. Dalam langkah ini, peneliti memilih Koefisien cepstral frekuensi Mel (MFC). Dengan menggunakan MFCC, model akan dapat menganalisis frekuensi suara pada data dalam karakteristik berbasis waktu. Ini karena MFCC meringkas distribusi frekuensi pada durasi data. Gbr. 4 adalah visualisasi MFC jika dibandingkan dengan spectrogram
Dalam proses ini, kita akan mengekstrak nilai numerik dari MFCC. Untuk ekstraksi MFCCs kita akan mengambil 40 koefisien dari data audio . Peneliti juga akan menentukan 431 sebagai jumlah maksimum fitur yang dapat diekstraksi dari data. Jadi, setelah transformasi, bentuk data peneliti adalah matriks dua dimensi 40 oleh 431.
Eksperimen
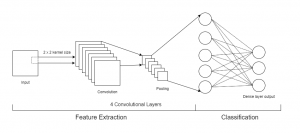
Untuk penelitian ini, peneliti memilih untuk menggunakan model konvolusional dengan empat lapisan. Lapisan konvolusional dapat mendeteksi fitur dari data dengan mengarahkan kursor ke data pada ukuran jendela tertentu. Node ini adalah bagian dari model peneliti yang melakukan pelatihan dan prediksi berdasarkan data. Untuk model , setiap lapisan konvolusional akan memiliki jumlah node yang meningkat. peneliti akan menggunakan 16 node di lapisan input hingga 128 node pada lapisan akhir. Dalam model ini, akan menerapkan lapisan pooling. Lapisan pooling ini akan dikaitkan dengan masing-masing lapisan konvolusional untuk mengurangi dimensi model. dengan mengurangi dimensi, peneliti juga akan mengurangi waktu yang dibutuhkan untuk pelatihan. data akan dibagi menjadi data pelatihan dan pengujian. Untuk data pelatihan, Peneliti akan menggunakan 80% dari set data dan untuk data pengujian, Peneliti akan menggunakan 20% dari set data. Untuk proses validasi, Peneliti akan menggunakan akurasi untuk mengukur kinerja model pembelajaran mesin yang diteliti.
Hasil
Model yang dihasilkan dengan prediksi sebagai berikut, pada data pelatihan, model peneliti dapat memprediksi suara kucing dengan benar 88,473254% persen dari waktu, tetapi pada data pengujian , model hanya dapat memprediksi 70. 80734% persen dari waktu. Ini berarti ada sekitar 20% perbedaan antara kinerja model pada data pelatihan dan data pengujian.
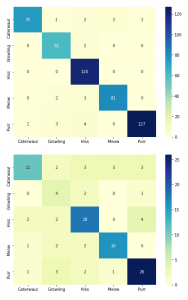
Perbedaan antara akurasi pelatihan dan akurasi pengujian ini dapat terjadi karena overfitting yaitu ketika model peneliti terlalu terbiasa dengan data pelatihan. Peneliti menyimpulkan bahwa ini terjadi karena set data memiliki terlalu sedikit data dan model, tidak dapat melakukan proses pelatihan secara efektif.
Untuk meningkatkan akurasi model, melakukan dengan data baru, lalu perlu meningkatkan jumlah data yang digunakan untuk pelatihan dan menyeimbangkan data, sehingga setiap label memiliki ammount data yang sama dan menerapkan metode augmentasi data pada data.
Intisari Penelitian
Peneliti berusaha membangun model jaringan saraf konvolusional yang mampu melakukan klasifikasi suara dari berbagai jenis suara kucing.Model peneliti mampu berkinerja baik dengan menerapkan transformasi koefisien cepstrum frekuensi mel pada data suara. Dari proses pelatihan, model peneliti mampu menghasilkan akurasi yang relatif tinggi jika dibandingkan dengan studi lain dengan metode yang berbeda, ketika mempertimbangkan jumlah data terbatas yang tersedia dan waktu terbatas untuk proses pelatihan. Masalah yang peneliti temukan dalam penelitian ini adalah bahwa dalam model, karena terbatasnya jumlah data dan keadaan set data yang tidak seimbang, model sedikit terlalu sesuai dengan data pelatihan. Di masa depan, peneliti ingin meningkatkan model dengan memperluas set data dan bahkan keluar setiap kategori yang berbeda, serta menerapkan augmentasi suara untuk mengurangi overfitting dan meningkatkan akurasi model .
|
Editor |
Octi Wulandari |
|
Peneliti |
Ridi Ferdiana dan William Fajar |
|
Tahun |
2020 |
|
Tautan Publikasi |




{kind=link}
{kind=link}
{kind=link}