Proses pengembangan aplikasi dalam lingkup kerangka kerja Agile membutuhkan pendefinisian produk secara cepat dan iteratif untuk mengembangkan produk secara berkala. Proses Requirement Elicitation dalam pengembangan produk merupakan proses penting dalam desain produk yang dilaksanakan oleh Product Manager dengan klien. Untuk menghasilkan perkembangan yang dilakukan secara iteratif, proses Requirement Elicitation perlu dilakukan secara rutin sesuai dengan durasi sprint pada metodologi Agile dalam bentuk meeting antara Product Manager dengan klien. Perkembangan yang terjadi pada setiap iterasi perlu didefinisikan secara jelas dan ringkas untuk dapat didokumentasikan menggunakan aplikasi development tools untuk mencatat perkembangan dan pembagian kerja secara tepat waktu dalam mengembangkan aplikasi sesuai dengan kebutuhan klien. Dalam lingkungan Agile, biasanya analis/Product Manager akan mendeskripsikan kebutuhan pengguna ke dalam daftar user story. User story ini mendeskripsikan kebutuhan-kebutuhan apa saja yang dimiliki oleh sistem.
Percakapan yang terjadi pada saat diskusi dalam sebuah meeting antara Product Manager dengan klien tidak akan selalu berjalan secara lancar. Pada umumnya, terdapat kesenjangan pemahaman ataupun pola bahasa yang digunakan oleh klien dengan Product Manager sehingga muncul kebutuhan yang dapat diatasi oleh penengah berupa aplikasi otomatis yang mendeteksi user story berdasarkan pola-pola yang muncul dari pembicaraan kedua belah pihak. Selain itu, permasalahan yang juga sering terjadi adalah ketidaklengkapan user story yang dihasilkan oleh Product Manager atau analis. Masalah-masalah ini tentu dapat menyebabkan produk atau output dari proyek pengembangan yang dilakukan tidak sesuai dan banyak kebutuhan pengguna yang tidak ikut disertakan oleh tim pengembang aplikasi.
Penyusunan user story didasarkan pada format Connextra yang dipopulerkan oleh Mike Cohn. Format Connetra merupakan user story yang tersusun atas 3R berupa role, requirement, reason dengan contoh pola kalimat statik seperti berikut:
“As a <Role> , I want to <Requirement>, so that I <Reason>.”
Menggunakan format yang dipopulerkan oleh Mike Cohn tersebut, program akan menyeleksi kalimat masukan dan menyesuaikan masukan semirip mungkin dengan format Connextra. Role sebagai masukan peran pengguna tidak selalu diutarakan dalam percakapan dengan klien sehingga perlu ditentukan secara manual. Kemudian, Requirement muncul pada saat klien mengutarakan keinginan atau kebutuhan dalam percakapan sehingga dapat dilacak klasifikasinya menggunakan keyword analysis. Reason pada percakapan muncul setelah pengutaraan modal verb diucapkan oleh pengguna sehingga membagi kalimat yang berpotensi menjadi user story menjadi dua komponen klausa.
Pengumpulan dataset dilakukan pada golongan Product Manager berpengalaman yang dapat mensimulasikan meeting Requirement, dengan menggunakan bahasa Inggris. Product Manager terkait kemudian memberikan hasil user story yang valid dari transkrip meeting sebagai tolok ukur yang dapat dibandingkan dengan keluaran akurasi. Rekaman meeting disimpan dalam format .wav sebagai bentuk format yang dapat dikerjakan oleh API Speech to Text.
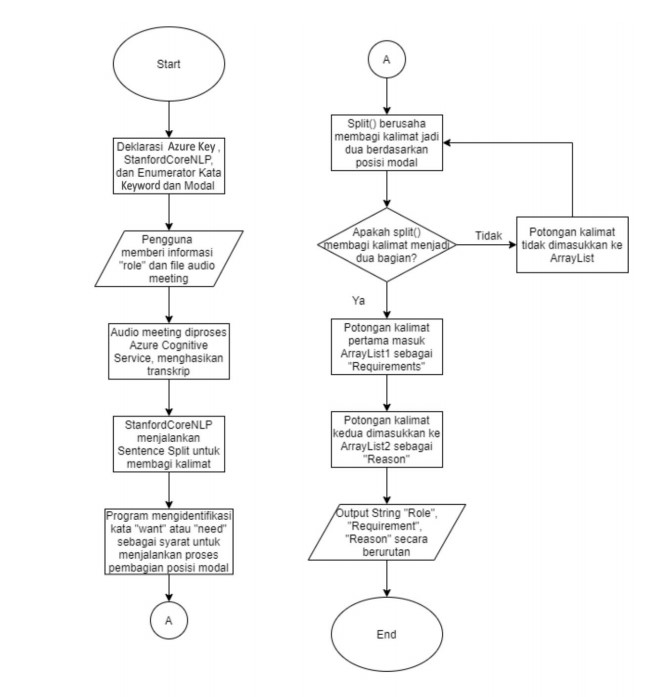
Pengolahan dataset dimulai dengan cara mengakomodasi artefak rekaman supaya dapat diproses oleh program Java, API Azure Cognitive Service, dan aplikasi pengolah file Excel. Artefak rekaman meeting pada umumnya berukuran sekitar 120 MB, dengan durasi sekitar 10 menit, sehingga perlu dikenakan kompresi file menggunakan Audacity untuk mengecilkan bitrate file audio dari 32 kHz menjadi 8 kHz dengan hasil kompresi file dari ukuran semula sebesar 75%. Kemudian program Java diberikan konfigurasi pada file ‘application.properties’ supaya Servlet dapat mengakomodasi file hingga ukuran maksimal yaitu <100 MB. Artefak rekaman meeting kemudian diproses menggunakan API Azure Cognitive Services Speech to Text untuk menghasilkan transkripsi teks yang dapat diolah menggunakan punctuation dan sentence splitter. Untuk setiap kalimat yang dikembalikan oleh API menggunakan listener pada method startContinuousRecognitionAsync(), aplikasi akan menjalankan algoritma generasi user story yang mendeteksi penekanan kata kunci atau keyword analysis dari kata “want” dan “need” untuk mengenerasi user story. Penekanan kata “want, need” ditentukan sesuai dengan format Connextra yang mencontohkan format menggunakan “want” atau “need” pada kalimat user story. Jika kata “want, need” terdeteksi, maka program akan menjalankan fungsi yang disediakan oleh java.lang.String.split() untuk mencari modal verb untuk membagi kalimat menjadi dua klausa yang dibagi berdasarkan posisi modal verb. Kedua klausa tersebut akan dicakup oleh dua ArrayList yang kemudian disusun ulang menjadi user story yang mana hasil basis data dapat dikonversi menjadi file Excel menggunakan Apache POI HSSF.
Uji akurasi transkripsi menggunakan pendekatan Word Error Rate (WER). WER merupakan pendekatan standar yang digunakan untuk mengevaluasi sistem large vocabulary continuous speech recognition (LVCSR). Pendekatan ini memperhitungkan total pergantian kata (s), penambahan kata (i), pengurangan kata (d), dan total kata sebenarnya pada audio (n).
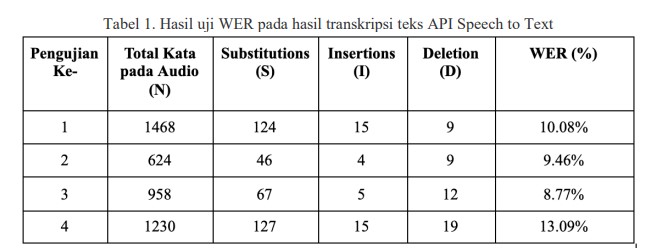
WER yang bernilai 5-10% tergolong memiliki kualitas yang cukup baik dan layak untuk digunakan dan WER yang berada diatas 20% masih harus membutuhkan training tambahan.
Kesimpulan pertama dari uji akurasi ini adalah nilai WER yang dihasilkan dari keempat pengujian tergolong baik dan layak digunakan sebagai transkrip untuk diolah menjadi kandidat-kandidat user story.
Pengujian akurasi kandidat user story dilakukan dengan membandingkan output yang dihasilkan sistem dan user story yang dihasilkan langsung dari partisipan atau product manager. Dari hasil ringkasan didapat bahwa rata-rata akurasi kandidat user story yang dihasilkan dari pengujian ini memiliki nilai 76.17%.

Beberapa user story yang tidak berhasil dihasilkan sistem dikarenakan terdapat kesimpulan-kesimpulan secara tersirat yang didapatkan oleh partisipan, klien tidak secara eksplisit
mengatakannya, atau klien tidak menggunakan kata-kata yang menjelaskan keinginannya menggunakan kata want atau need. Beberapa output yang dihasilkan sistem bukan merupakan
kandidat user story yang dapat digunakan oleh pengguna. Namun karena penggunaan kata want yang diucapkan oleh klien, sistem otomatis mengambil dan mengira bahwa kalimat tersebut dapat digunakan sebagai kandidat user story. Kesalahan-kesalahan dari kandidat user story seperti ini dapat dengan mudah diabaikan oleh pengguna, sehingga pengguna disarankan hanya mengambil kandidat user story yang cukup relevan untuk digunakan dalam proses pengembangan produk mereka. Nilai akurasi yang dihasilkan dari pengujian ini terbilang cukup untuk pengembangan pertama dan dapat dikembangkan lebih lanjut kedepannya.
Pembentukan user story dari meeting yang dilakukan pada proses Requirement Elicitation dalam metodologi Agile dapat diotomatisasi menggunakan aplikasi pembangkit user story, Aplikasi tersebut menggunakan algoritma yang didasarkan pada keyword analysis yang memberikan penekanan pada keinginan atau kebutuhan pengguna dan modal verb untuk membentuk user story sesuai dengan format Connextra.
Penulis juga menyadari dalam proses dan hasil implementasi masih terdapat beberapa penyempurnaan yang dapat dikembangkan seperti:
- Pengiriman email kepada pengguna ketika kandidat user story selesai dihasilkan oleh sistem
- Penambahan format audio yang diizinkan untuk diunggah tanpa mengurangi kualitas file
- Improvement algoritma pembangkit kandidat user story yang lebih baik lagi agar akurasi semakin meningkat
Peneliti: Meilisa H. Narpati Nadi, Ridi Ferdiana, Selo
Tahun 2021



